# openAI公司
- 一个研究组织,致力于以负责任和安全的方式推进人工智能的发展;
- 于2015年,由一群著名的科技领袖成立;
- 至今,带来很大的轰动的两大模型:GPT3大模型,DALL-E大模型
# DALL-E大模型
- 一个基于神经网络的图像生成模型。
- 由艺术家萨尔瓦多一达利与玩具wall-e命名而成;与达利的超现实主义会话有关;
# chatGPT背后的男人
- 伊利亚-苏茨克沃(Ilya Sutskever),OpenAI的联合创始人和首席科学家,辛顿教授的高徒;
- 2005年毕业于多伦多大学,2012获得CS博士学位;
- 2011年,第一次接触AGI(通用人工智能,Artificial General Intelligence),但认为太过虚幻而没有接触,并于2013加入谷歌
- 2012年,辛顿教授作为深度学习的拥簇者,在斯坦福大学举办的ImageNet竞赛中,采用深度神经网络,赢得比赛,使人们看到了深度学习的希望,图像识别领域焕然一新。某种程度上,也让其团队接触到暴力美学,或者说大力出奇迹。
- 他与其老师辛顿,建立了一家DNNresearch的公司,并拍卖给谷歌,随后其成为谷歌大脑的研究科学家,并开始相信AGI.毕竟相信AGI是信仰之跃.
- 2014年,任谷歌大脑期间,发明了一种神经网络的变体,能将英语翻译成法语,击败了表现最好的翻译器。提出序列到序列学习。
- 2015年,放弃谷歌百万美元年薪机会(是当时OpenAI的两三倍),成为OpenAI联合创始人;为了热情与激情,抵挡住了物质诱惑,堪称研究人员的典范。
- 2018年,在他的带领下,发布GPT-1模型
- 2019年,使用更大数据集进行训练,发布GPT-2模型
- 2020年,使用大规模数据集进行训练,使用了1750亿个参数,发布GPT-3大模型
- 2021年,领导OpenAI发明了DALL-E 1图像生成模型,今天的主要图像生成器,如DALL-E 2以及MidJourney都是基于类似的变换器架构进行训练的.
- 2022年11月30日,推出ChatGPT,一度成为现象级爆款;该模型是基于GPT-3大语言模型.
# GPT系大模型的发展
# GPT-1
- 于2018年发布该模型,采用了12层的Transformer Decoder结构,大约5GB的无监督文本数据进行训练
- 逊色于同期的bert模型
# GPT-2带来了希望
- 2019年,发布带有48层Transformer结构的
GPT2模型 - 发现它通过大量语料的无监督训练,它突然会做翻译了,这个发现或多或少带有颠覆性的意味
- 该现象,给当时的科学家们和研究人员一些线索:
- 完成一种NLP任务,也许并不需要和任务匹配的标注数据
- 完成一种NLP任务,也许并不需要和任务匹配的训练目标
- 仅仅生成式任务训练的模型,也可以具有多任务的能力;
- GPT2虽然有着翻译、摘要等能力,但效果太差,以至于无法实际使用,但它带来了阶段性的突破
# GPT-3数据飞轮的开始
- 2020年,发布了具有1750亿参数量的GPT3,一个即便以现在的眼光去看也大得惊叹的模型
- 估算约花费1200万美元
- 该模型最惊人的发现是,模型具有了小样本学习的能力
- 小样本学习的能力,类似于人类可以通过少量的几个例子,就能够学会一个新的语言任务,如把字句改为被字句;
- 后来该能力被称为在上下文中学习的能力,它被证明是巨型模型所特有的
- 2020年,GPT3模型已经对外提供服务,越来越多优质的数据用于学习,数据飞轮开始转起来了
- 它的交互模式是,用户提供一些文字,模型接着往下续写,与如今的chatgpt多轮对话有所不同
# CodeX,让计算机自己写代码
- 对GPT的研究,有一个意外的发现,它能够根据一些注释生成简单的代码,随后的2021年,对生成代码这件事,进行专门研究,并发布了CodeX模型;
- CodeX是一个有代码专精能力的GPT模型,能够根据自然语言,生成比较复杂的代码;
- 其训练过程是,利用经过文本预训练的GPT模型,在抓专门的代码数据(github的开源代码,约159G)进行训练,用的是120亿参数的小模型
- 根据后续的研究,增加对代码数据的训练很可能触发了后来的GPT模型在自然语言的复杂推理和思维链的能力
# InstructGPT,让GPT好好说话
- GPT模型具有一本正经的胡说八道和输出带有危害性的内容这两个最严重的缺点
- 2022年初,发布InstructGPT,核心理论是让模型接受人类的教导(反馈);
- InstructGPT提出了两个阶段的路径,来让模型学习人类的优秀范例,第一阶段是监督学习,第二阶段是强化学习
- 监督学习阶段,人类根据不同的Prompt,写真实的,无害的,有用的回答;类似于语文老师让我们默写优秀范文;
- 强化学习阶段
- 第一步,让模型根据不同的Prompt生成多个不同的回答,并由人来给这些回答由好到差的标准进行排序,然后用这些标注了优劣之分的数据训练一个打分模型,让其可以自动给更多的数据排序打分;
- 第二步,利用排序在前的优秀数据,作为监督学习的数据,继续训练模型。 形成一个迭优闭环;
# GPT-3.5时代和ChatGPT的诞生
随后,发布了多个被称为GPT-3.5的模型,它是融合了OpenAI在GPT3时代积累的技术、数据及经验开发出来的
据分析,GPT3.5系列的模型,有可能不是从GPT3继续微调而来,而可能是将代码和自然语言的数据融合在一起,重新从零开始训练的一个基础模型;
- 该模型可能比GPT-3的1750亿参数数量更大,在OpenAI的API中被命名为
codex-davinci-002,在这个模型的基础上,通过指令微调和人类反馈,得到一系列的后续模型,包括ChatGPT.
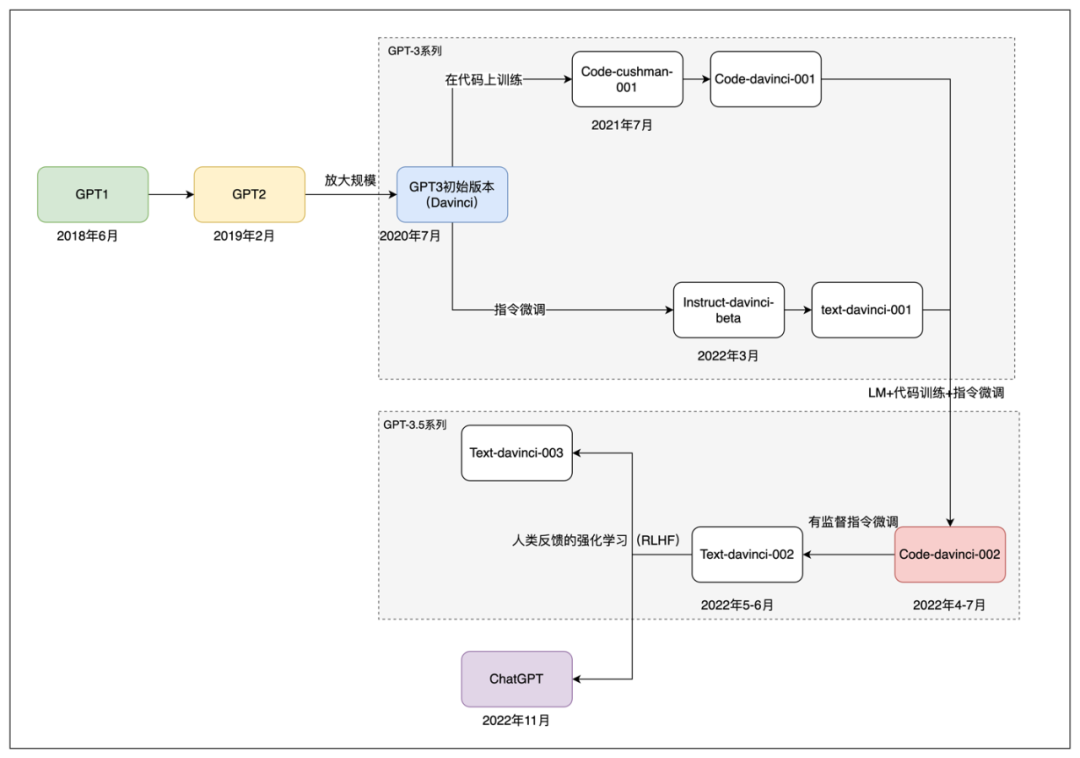
- 该模型可能比GPT-3的1750亿参数数量更大,在OpenAI的API中被命名为
# ChatGPT技术人的冷静思考
# 人工智能带来的震撼
- 第一次让人类觉得,人工智能似乎终于能够和人正常交流了,它能懂你在说什么!,给人带来很强的智能感.
- 它能够将自然语言的理解,转换为数学问题的能力,能够将一个复杂的推理问题拆解,一步步获得最后的答案,被称为思维链;
- 它打破了特定场景和特定任务,实现了某种程度智能的泛化(AGI,泛人工智能)
# ChatGPT的主要能力分类
# 文本生成的能力
- ChatGPT在训练时,是一个标准的自回归语言模型任务,它通俗的理解是:根据已经输入的文本,预测下一个token应该是什么
- 我们在使用ChatGPT的时候,它的工作方式与其训练方式一样,模型根据我们在输入框输入的内容,预测接下来这些内容的token是什么,依次迭代,直至满足某个条件后停止;
- 从模型的学习过程看,它并没有学习自然语言中所蕴含的信息、逻辑、情感,而知识简单的学习根据输入的文本,一个人类在后面会接着写什么这件事;
# 丰富的知识储备
- ChatGPT能够正确回答很多问题,因为这些知识是存储在模型内部的;
- 可以粗浅的理解为:数据的内容以及模型的各项能力,都以一个参数的具体数值的形式,固定在了训练完成的模型中
# 逻辑推理与思维链的能力
- 它能够将复杂的内容,通过拆解,分成多个小的步骤,一步步推理,获得答案,这种能力被称为思维链;
- 主流观点认为,逻辑推理和思维链可能和两个因素有关
- 模型的体量,是否足够大
- 模型是否在代码数据上进行了训练
# 按照人的提问或指令给予回复的能力
- 除了按照狭义问答的方式进行回答外,还能够按照**输入的要求(指令)**进行回答
- 单就ChatGPT而言,回答知识性问题,并不是它的强项;
- 它的强项在于,是一个语言完备的文本工具,即它能够按照你的要求,完成指定的,可以用文本形式表达出来的内容
- 语言完备,指的是运用语言的能力,如遣词造句,语种切换,邮件格式等
- 根据指令(prompt)进行回复的能力,来自于一种被称为指令微调(prompt tuning)的模型训练方式;
# 客观公正的能力
- 当询问一些有害,或者有争议的内容,模型回答的非常小心,这种能力是OpenAI敢将它作为一款公共产品使用的核心因素.
- 该能力由监督学习,强化学习共同获得
# chatGPT的未来展望
- 圈外的大众,更多是以好奇、惊讶、惊叹的方式来感性的认识它的出现
- 对从业者来说,更多的是对未来技术走向的思考
- 从技术的角度看,ChatGPT的出现标志着NLP领域又一次范式切换
- ChatGPT类模型的出现,大大降低了NLP技术的应用门槛,其目前弊端在于缺少准确可靠的垂直领域知识.
# 国产化的启示
- 从技术的角度,ChatGPT的内容是已知的,但其依然拥有如此惊艳的表现,考虑如下一些因素
- 数据量的因素
- 数据质量的因素
- 训练过程的影响,考虑集群训练,并行训练